
A Deep Dive in KVM Hypercall
As we know, paravirtualization hypervisors (such as Xen) prevent a guest from messing up the whole host by having guests actively calling “hypercalls” to the hypervisor. Through the hypercall, the hypervisor would take care of the guest’s needs, such as setting the current code stack for a vCPU, in a secure way. The most obvious trade-off of such a method is that it requires the guest to recognize itself in a virtualized environment, which is not suitable to many operating systems originally designed to run on bare metal if no modifications to the guest os are made.
KVM (Kernel based Virtual Machine) works only in hardware-assisted virtualization, like Intel VT or AMD-V, which is still quite different from the traditional paravirtualization in that it does not rely on hypercall to keep guests in the safe zone, instead, it is CPU which catches sensitive instructions from the guests and puts itself into the root mode to let the KVM handle it. However, KVM still makes use of the hypercall mechanism to improve its performance and this has become an unignorable part of it.
Why need hypercall
Ok, let’s first take one of the hypercalls it supports – KVM_HC_KICK_CPU as an example to illustrate how it can benefit virtualization performance.
SpinLock problem in virtualization
Spinlock is a low-level lock mechanism, when a thread tries to acquire a lock that is not released yet, it will just keep waiting and checking (which is also called “spin”) until the lock is released without being preempted by the operating system. This is good for the waiting thread because it saves cost of being rescheduled, but the advantage is only effective when the expected waiting time is shorter than a quantum. If the thread takes too long for spinlock waiting, it just wastes too much CPU time that could be used to run other threads.
Now let’s suppose a spinlock is running in a guest on KVM, there will be two problems:
-
Lock Holder Preemption problem: when one of the guest’s vCPUs(a vCPU is a thread) has acquired a spinlock and gets preempted by the OS, at this point, another vCPU waiting for this lock to be released will still be taking the CPU time for busy-waiting. Other vCPUs trying to use this CPU will get less execution time, but since the holding of a spinlock in linux would usually very short, the chance of the lock holder getting preempted is very low.
-
Ticket Lock problem: this one is more complicated and serious. For a ticket lock that is not currently released, there could be multiple vCPUs waiting in an oerdered line to take the lock (FIFO). What if the lock is released but the next scheduled waiting vCPU is not the next waiter in the line (since the vCPU scheduler does not schedule according to the lock waiting line)? It will still keep spinning, wasting the CPU time. This means the total lock waiting time may include not only the occasions the holder’s vCPU gets preempted, but also when the “wrong” (that is not the next in the line) vCPU gets scheduled and spin.
How hypercall solved it
To resolve the problems above, KVM has introduced a hypercall KVM_HC_KICK_CPU, let’s see how it works:
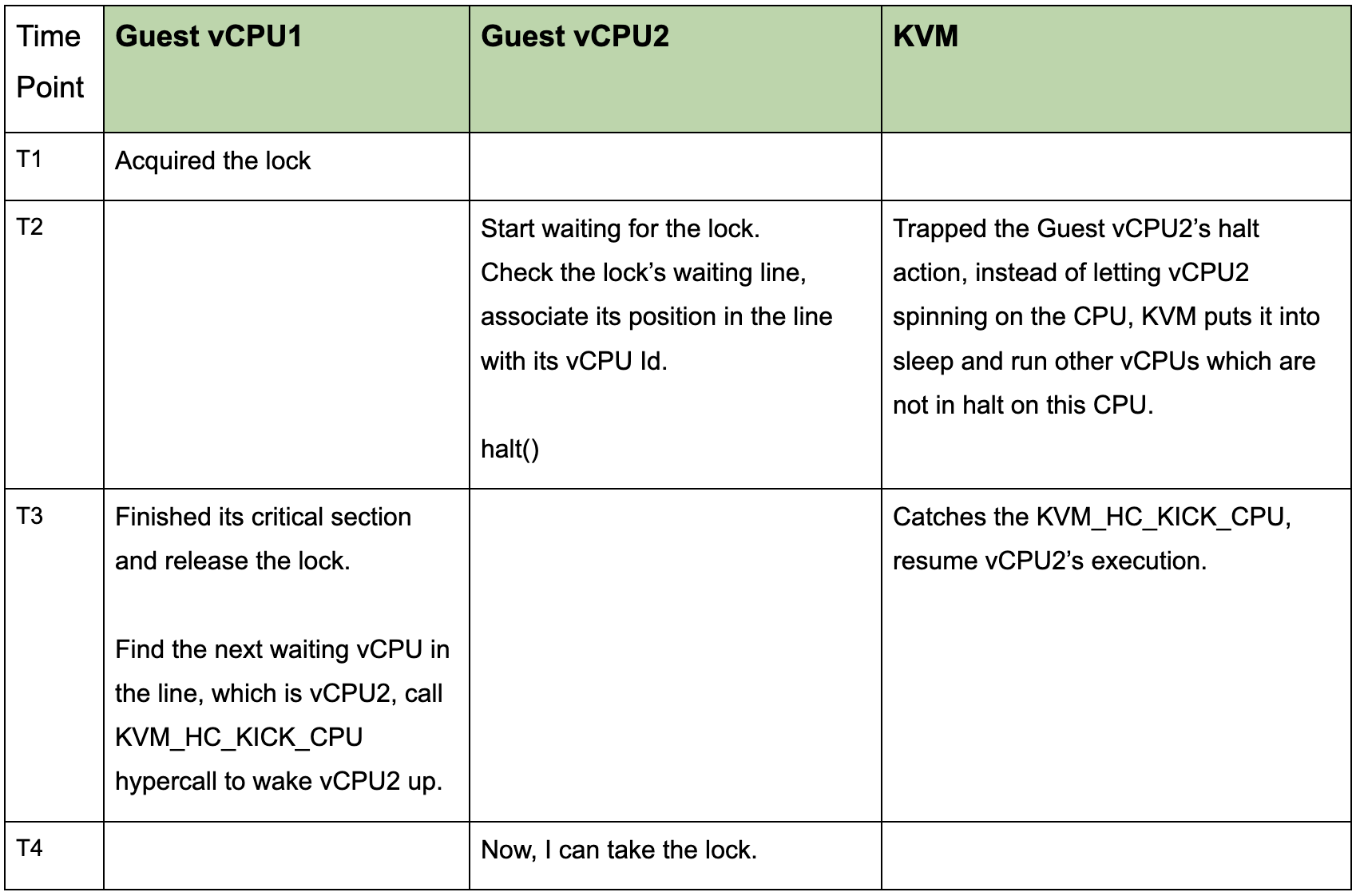
From the timeline above, we can see that the lock holder in the guest tells KVM, through hypercall, to wake up the right vCPU when releasing the ticket lock. In this way, the problem of scheduling the “wrong” vCPU from the waiting queue and wasting CPU time on spinning can be avoided.
How hypercall works in KVM
Hypercall call path
Having explained how one of KVM’s hypercalls benefit the performance of virtual machines, let’s go through the process of a hypercall’s calling path. Intel and AMD both have their implementation of hypercall, they provide an individual instruction, which is “vmcall” in Intel and “vmmcall” in AMD, for the guest to execute. When such instruction is executed, it’s intercepted and CPU will cause a vm-exit to pass the control to KVM. Below is a normal execution flow:
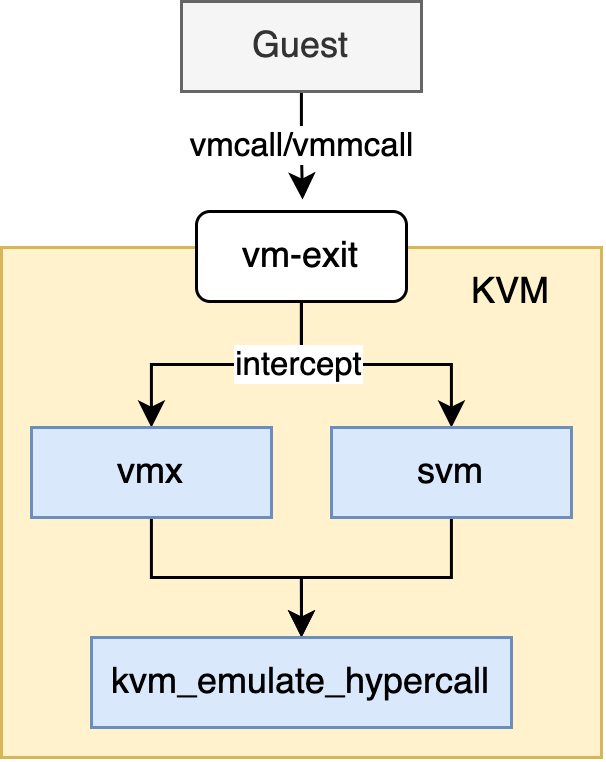
hypercall flow
In kvm_emulate_hypercall, KVM will obtain which hypercall is made by reading from rax register. Also more arguments associated with this hypercall are read from rbx, rcx, rdx and rsi registers. For example, for the KVM_HC_KICK_CPU hypercall we talked above, arguments are the flag and the APIC id of the vCPU to wake up.
Hypercall fixing
Ok, here is a question, as we mentioned above, intel and AMD provide different instructions for the guest to make the hypercall (vmcall and vmmcall), what if the guest makes the wrong hypercall that the current CPU does not support? There is another mechanism “patch hypercall” in KVM that is meant to fix the wrong hypercall instruction to the right one. Here is a flow of “patch hypercall“ in the KVM running in AMD’s SVM:

hypercall fixing
Let’s say, the guest made an vmcall on AMD CPU (which only supports vmmcall). First, the wrong instruction will cause CPU to raise an #UD (Invalide Opcode) exception and a vm-exit is triggered. For UD exception, SVM will let the KVM try to decode and emulate such exception, replacing this instruction with one or multiple desired instructions. The interface patch_hypercall is actually implemented separately in VMX and SVM because the instruction it is patching is related to the specific CPU vendor. In this case, SVM will replace the vmcall instruction with vmmcall, then KVM will write the patched instruction to the guest’s vCPU stack and let the guest re-execute the corrected vmmcall instruction again. Then the process will get back to the normal hypercall flow.
Interestingly, linux kernel used to have exactly the same “wrong hypercall” problem as we described above – the vmcall instruction is executed on AMD CPU when the guest is trying to make the KVM_HC_KICK_CPU hypercall for its spinlock. Would the instruction be successfully fixed and everything is fine? Well it’s not that easy. There is a configuration item CONFIG_DEBUG_RODATA when building kernel, turning it on will make the memory which stores kernel code read-only. In most production linux distributions, this is turned on. In such case, when going through the hypercall fixing path described above, the KVM will actually fail to write the patched instruction to the guest’s stack. When trying to write to the memory address that stores the instruction, the KVM will not be able to get a translated guest physical address from the guest virtual address because that one is read-only and it will propagate error to guest, leading the guest to crash. Therefore, there was a patch trying to solve this problem by having the guest execute the right hypercall instruction in the first place.